As most of us in the Julia community know, Julia has an issue. In fact, looking at the Julia repository we see that there are (at time of writing) 11865 issues, where 1872 are open and 9993 are closed. An interesting question to ask is:
- How has the ratio between open and closed issues varied over the development of Julia? And how about for pull requests (PRs)?
In this post, the aim is to answer the question above using the data that can be scraped from the GitHub repo.
Getting the data
A large amount of data for a repository hosted on GitHub can be found via the GitHub API. The GitHub.jl package provides a convenient interface to communicate with this API from Julia.
Getting the data for the issues (and PRs) is as simple as:
import GitHub
myauth = GitHub.authenticate(ENV["GITHUB_AUTH"])
repo = GitHub.repo("JuliaLang/julia")
myparams = Dict("state" => "all", "per_page" => 100, "page" => 1);
issues, page_data = GitHub.issues(repo; params = myparams, auth = myauth)
where I have created a “GitHub access token” and saved it in the environment variable GITHUB_AUTH. Note here that the function name GitHub.issues is a bit of a misnomer.
What is returned is actually both issues and PRs.
The variable issues now contains a Vector of all the issues and PRs made to the Julia repo.
Each element in the vector is an Issue, which is a struct containing fields
corresponding to the keys of the returned JSON from the GitHub REST API.
In order to not have to rescrape the data every time Julia is started, it would be nice to
store it to disk. The standard way of storing Julia data is by using the *JLD.jl package.
Unfortunately, JLD.jl has some problems handling Nullable’s (see this issue).
However, there is an unregistered package called JLD2.jl
that does support Nullable’s. The code below uses JLD2 to save the issues to a .jld file
and then reload them again:
using JLD2
function save_issues(issues)
f = jldopen("issues.jld", "w")
write(f, "issues", issues)
close(f)
end
function load_issues()
f = jldopen("issues.jld", "r")
issues = read(f, "issues")
close(f)
return issues
end
I put up the resulting .jld file here if you don’t feel like doing the scraping yourself.
Digression: a DateVector
In this post we will deal with Vector’s that are naturally indexed by
Date’s instead of standard integers starting at 1. Therefore, using the powerful
AbstractVector interface
we easily create a Vector that can be indexed with single Date’s ranges consisting of Date’s etc.
The implementation below should be fairly self explanatory. We create the DateVector struct
wrapping a Vector and two Date’s (the start and end date) and define a minimum amount of methods needed.
Vector’s with non conventional indices are still quite new in Julia so not everything work
perfectly with them. Here, we just implement the functionality needed
to set and retrieve data using indexing with Dates.
struct DateVector{T} <: AbstractVector{T}
v::Vector{T}
startdate::Date
enddate::Date
function DateVector(v::Vector{T}, startdate::Date, enddate::Date) where T
len = (enddate - startdate) ÷ Dates.Day(1) + 1
if length(v) != len
throw(ArgumentError("length of vector v $(length(v)) not equal to date range $len"))
end
new{T}(v, startdate, enddate)
end
end
Base.endof(dv::DateVector) = dv.enddate
Base.indices(dv::DateVector) = (dv.startdate:dv.enddate,)
Base.getindex(dv::DateVector, date::Date) = dv.v[(date - dv.startdate) ÷ Dates.Day(1) + 1]
Base.setindex!(dv::DateVector, v, date::Date) = dv.v[(date - dv.startdate) ÷ Dates.Day(1) + 1] = v
Base.checkindex(::Type{Bool}, d::Range{Date}, v::Range{Date}) = length(v) == 0 || (first(v) in d && last(v) in d)
Base.Array(dv::DateVector) = dv.v
The DateVector can now be seen in action by for example indexing into it
with a Range of Date’s:
julia> v = rand(10);
julia> dv = DateVector(v, Date("2015-01-01"), Date("2015-01-10"));
julia> dv[Date("2015-01-02"):Date("2015-01-05")]
4-element Array{Float64,1}:
0.299136
0.898991
0.0626245
0.585839
julia> v[2:5]
4-element Array{Float64,1}:
0.299136
0.898991
0.0626245
0.585839
Total number of opened and closed issues / PRs over time
For a given issue we can check the time it was created, what state it is in (open / closed), what time it was eventually closed and if it is, in fact, a pull request and not an issue:
julia> get(issues[1].created_at)
2017-05-23T18:09:45
julia> get(issues[1].state)
"open"
julia> isnull(issues[1].closed_at)
true
julia> isnull(issues[1].pull_request) # pull_request is null so this is an issue
true
It is now quite easy to write a function that takes an issue and returns two Date-intervals, the first
for when the issue was opened, and the second for when it was closed up until today.
If the issue is still open, we make sure to return an empty interval for the closed period.
function open_closed_range(issue)
opened = Date(get(issue.created_at))
if get(issue.state) == "closed"
closed = Date(get(issue.closed_at))
else
closed = Date(now())
end
return opened:closed, (closed + Dates.Day(1)):Date(now())
end
As an example, we can test this function on an issue:
julia> open_closed_range(issues[200])
(2017-05-13:1 day:2017-05-14, 2017-05-15:1 day:2017-05-29)
So, here we see that the issue was opened between 2017-05-13 and 2017-05-14 (and then got closed).
Now, we can simply create two DateVector’s, one that will contain the total number of opened
issues and the second the total number of closed issues / PRs for a given date
function count_closed_opened(PRs::Bool, issues)
min_date = Date(get(minimum(issue.created_at for issue in issues)))
days_since_min_date = (Date(now()) - min_date) ÷ Dates.Day(1) + 1
closed_counter = DateVector(zeros(Int, days_since_min_date), min_date, Date(now()))
open_counter = DateVector(zeros(Int, days_since_min_date), min_date, Date(now()))
for issue in filter(x -> !isnull(x.pull_request) == PRs, issues)
open_range, closed_range = open_closed_range(issue)
closed_counter[closed_range] += 1
open_counter[open_range] += 1
end
return open_counter, closed_counter
end
For a given date, the number of opened and closed issues are now readily available:
julia> opened, closed = count_closed_opened(false, issues);
julia> opened[Date("2016-01-1")]
288
julia> closed[Date("2016-01-1")]
5713
We could plot these now using one of our favorite plotting packages. I am personally a LaTeX fan and one of the popular plotting packages for LaTeX is pgfplots. PGFPlotsX.jl is a Julia package that makes it quite easy to interface with pgfplots so this is what I used here. The total number of open and closed issues for different dates is shown below.
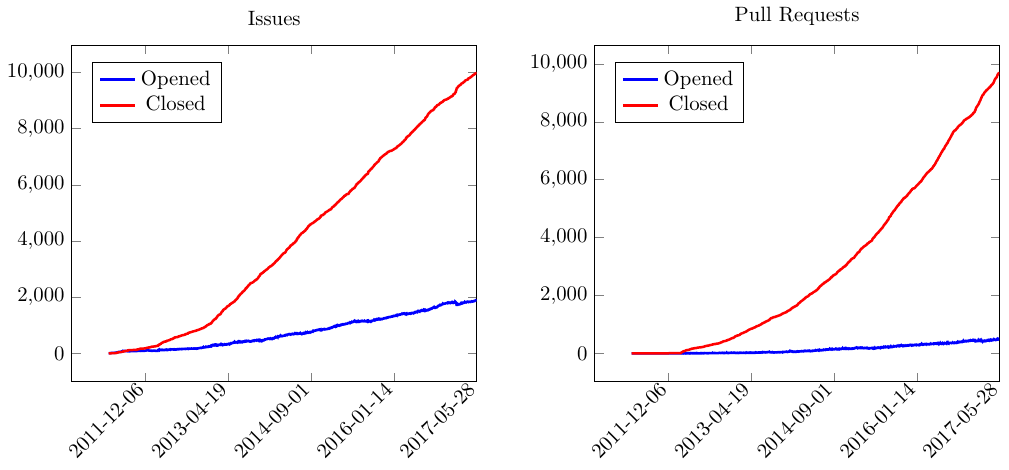
We can see that in the early development of Julia, PRs was not really used. Also, the number of closed issues and PRs seem to grow at approximately the same rate. A noticeable difference is in the number of opened issues and PRs. Open PRs accumulate significantly slower than the number of open issues. This is likely because an open PR become stale quite quickly while issues can take a long time to fix, or does not really have a clear actionable purpose.
Let’s plot the ratio between open and closed issues / PRs:
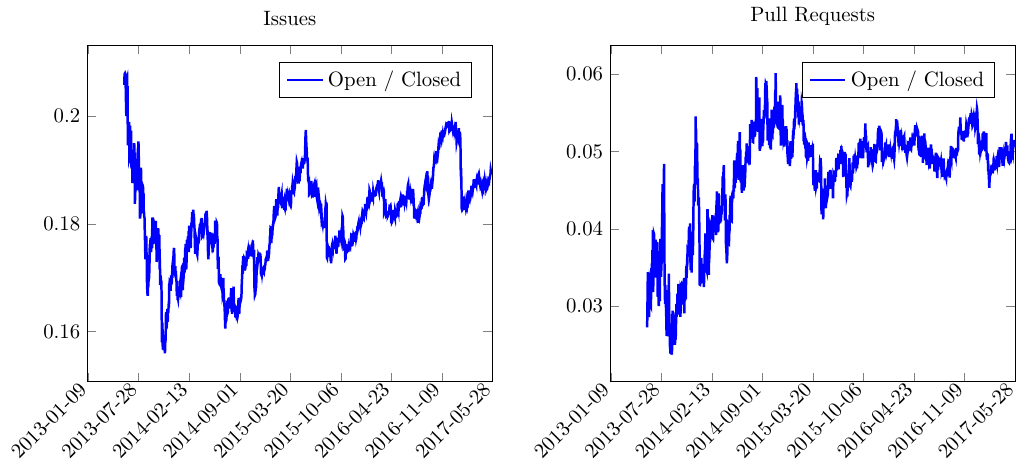
To reduce some of the noise, I started the plot at 2013-06-01. The ratio between open to closed issues seems to slowly increase while for PRs, the number have stabilized at around 0.05.
Conclusions
Using the GitHub API it is quite easy to do some data anlysis on a repo. It is hard to say how much actual usefulness can be extracted from the data here but sometimes it is fun to just hack on data. Possible future work could be to do the same analysis here but for other programming language repos. Right now, looking at e.g. the Rust repo they have an open to closed PR ratio of 63 / 21200 ≈ 0.003 which is 20 times lower than Julia. Does this mean that the Julia community need to be better at reviewing PRs to make sure they eventually get merged / closed? Or is the barrier to open a PR to Rust higher so that only PRs with high success of merging gets opened?